Evaluating GPT-Based Triage Chatbot Disposition Accuracy Against Expert Nurse Benchmarks Across Adult After-Hours Telehealth Guidelines
Authors
David A. Thompson MD, Senior Medical Editor, Schmitt-Thompson Clinical Content; Northwestern University Feinberg School of Medicine
Laurie O'Bryan RN, Nurse Editor, Schmitt-Thompson Clinical Content
Michał Remigiusz Janiszewski, Agentic AI/ML Engineer, VStorm
Background: Nurse telehealth triage is the process by which nurses assess patient symptoms, determine urgency, and guide patients to the most appropriate level of care. Schmitt-Thompson Clinical Content (STCC) telehealth triage guidelines provide a structured clinical decision-support framework for this process, with each guideline containing Triage Assessment Questions (TAQs) arranged in descending order of urgency and linked to recommended disposition levels. As large language model (LLM)-based chatbots emerge as potential tools to support or augment nurse triage, rigorous evaluation against validated clinical benchmarks is essential. This study evaluates the disposition accuracy of a GPT-based triage chatbot using the STCC guidelines tested against expert telehealth triage nurse benchmark data across 16 adult after-hours clinical guidelines.
Methods: Structured full-scenario (single-pass) testing was conducted by the STCC Digital Health Workgroup from August 2025 through March 2026. In full scenario mode, the chatbot received a complete clinical presentation and was evaluated on its ability to select the recommended triage guideline, identify the first positive TAQ, and reach the correct disposition.
The chatbot processes each clinical scenario using a four-stage workflow. First, an LLM agent extracts patient age and gender to filter the applicable guideline set. Second, a dedicated LLM agent identifies the primary and secondary reason(s) for visit. Third, the scenario is matched against a pre-indexed guideline vector store using retrieval-augmented generation (RAG), followed by LLM-based classification to select the most appropriate guideline. Fourth, TAQs are evaluated concurrently across all disposition levels (e.g., Go to ED Now, Home Care) using parallel LLM calls, with multi-part TAQs parsed using Boolean logic. Outputs include the recommended disposition, SOAP-formatted notes, and an optional LLM-generated rationale.
Clinical scenarios were developed and validated through a structured 14-step process. Nurse Editors initially drafted scenarios for each guideline; scenarios were revised or discarded in cases of editorial disagreement. The remaining scenarios were then submitted for validation testing by a panel of five expert telehealth triage nurses. Scenarios were retained only if the panel's aggregate Correct Recommended Disposition (CRD) rate was 95% or higher. Those meeting validation criteria were reviewed and approved by the Senior Medical Editor. In total 329 validated clinical scenarios across 16 adult after-hours telehealth triage guidelines were used to evaluate chatbot disposition accuracy. Chatbot disposition accuracy was compared against benchmark CRD rates established through the validation process. Three GPT model versions were evaluated across proof-of-concept builds v0.3.x through v9.1: GPT‑4.1, GPT‑5, and GPT‑5.1. Guideline content was delivered using two retrieval methods, pre-parsed PDF and relational database. These approaches were compared for both accuracy and scalability.
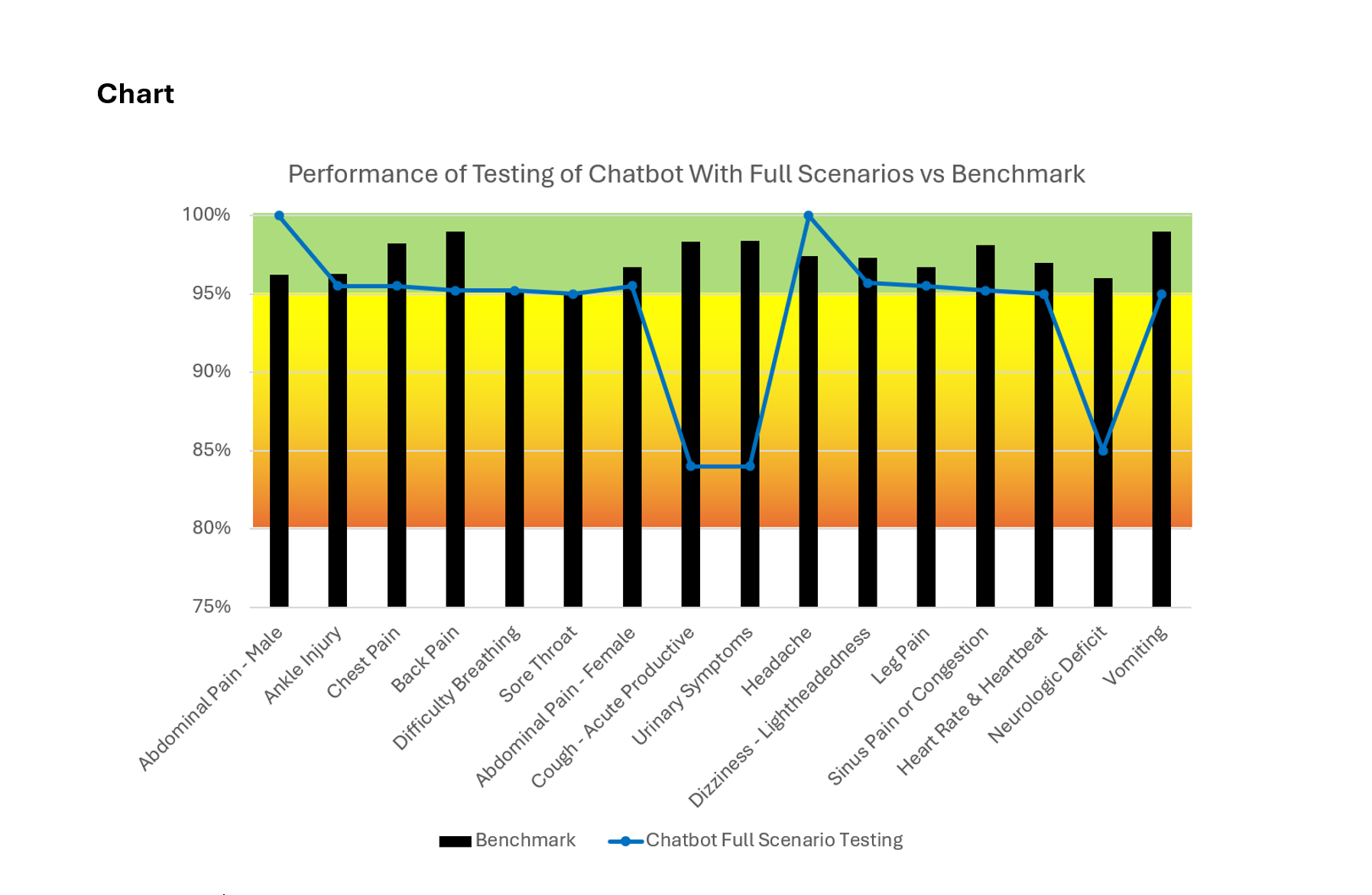
Results: Full-scenario disposition accuracy was strong across the majority of guidelines. Thirteen of sixteen guidelines demonstrated chatbot accuracy within five percentage points of their respective nurse benchmarks, indicating robust overall alignment with expert clinical judgment. Two guidelines exceeded the benchmark performance: Abdominal Pain - Male (100% vs. 96.2%) and Headache (100% vs. 97.4%). In contrast three guidelines underperformed nurse benchmarks: Neurologic Deficit (85.0% vs. 96.0%), Cough - Acute Productive (84.0% vs. 98.3%), and Urinary Symptoms (84.0% vs. 98.4%). Across all guidelines GPT 5 and GPT 5.1 consistently demonstrated higher disposition accuracy than GPT 4.1. Database retrieval outperformed pre-parsed PDF delivery in both accuracy and operational scalability. The most common failure mode involved scenarios with no positive TAQ identified. In these cases, the chatbot correctly selected a guideline but failed to match any TAQ to the clinical scenario. Additional errors were driven by incorrect guideline selection in cases involving overlapping or ambiguous chief complaints.
Conclusion: In full-scenario testing, the GPT-based triage chatbot demonstrated disposition accuracy comparable to expert nurse benchmarks across most adult after-hours telehealth guidelines. These findings support the potential role of LLM-based tools in assisting nurse-led telehealth triage. For example, such tools can be used before the nurse triage encounter starts to capture clinical information via AI chatbot intake, or during the nurse triage encounter via ambient listening technologies. Persistent failure modes, particularly lack of TAQ matching and guideline selection errors in clinically ambiguous presentations, remain important areas for further model refinement. Future development should focus on improving TAQ matching logic, resolving unknown-status errors, and expanding the library of clinical scenarios.
Citation
Thompson DA, O'Bryan L, Janiszewski MR Evaluating GPT-Based Triage Chatbot Disposition Accuracy Against Expert Nurse Benchmarks Across Adult After-Hours Telehealth Guidelines. March 2026.